
In this lecture, we will discuss gradient optimization methods for neural networks (and deep models in general).
Please study the following material in preparation for the class:
- Geoff Hinton’s coursera lectures 6.
- Chapter 4 and Chapter 8 of the Deep Learning textbook.
- Lecture slides. (covers SGD, SGD+momentum, Nesterov momentum, Adagrad, RMSprop, Adadelta)

L’optimisation réduit-elle la capacité d’un modèle?
LikeLike
La capacité d’un modèle c’est la taille de l’ensemble de fonctions dans lequel on pioche notre prédicteur. L’optimisation (ici la minimisation d’une fonction de coût) est notre méthode de recherche de la meilleure fonction dans cet ensemble, dans le cas d’un problème et un ensemble de données précis. Ce sont donc deux choses différentes. Sans changer la taille de l’ensemble de fonction, l’optimisation permet de se déplacer dans cet ensemble afin de trouver la fonction qui nous convient, par exemple parce qu’elle minimise l’erreur sur des données de validation.
En revanche le choix de la méthode d’optimisation et de ses paramètres influence la capacité d’un modèle. Par exemple en prenant un pas constant trop grand on n’accèdera certainement pas à des prédicteurs aussi précis que si on avait choisi un pas optimum ou un pas décroissant.
LikeLiked by 1 person
Je ne saisis peut-être pas la subtilité de la chose, mais si l’exemple d’optimisation en augmentant le pas empêche d’atteindre certaines fonctions c’est bien qu’il réduit d’une certaine manière la capacité du modèle, l’ensemble de fonction dans lequel on fait notre choix est réduit.
LikeLike
@tlesort L’optimisation n’est pas une méthode pour réduire la capacité, c’est un processus de recherche de meilleurs paramètres étant donné les présents. Des méthodes comme SGD, de par elle-mêmes, ne peuvent réduire la capacité d’un modèle.
Par contre, mal mener l’optimisation peut causer une réduction effective de la capacité. Choisir des valeurs d’hyperparamètres innappropriés fait partie de ces erreurs, tel un pas constant. Mais il faut être clair: Ce n’est pas la faute de l’outil qu’il fonctionne mal, si on en fait mauvais usage!
Dans le cas de la taille du pas, commencer avec un pas suffisament grand, et le recuire à mesure que l’optimisation progresse, permettra à l’optimisation de fonctionner à son plein potentiel. À nouveau, c’est preuve que l’optimisation ne limite pas, intrinsèquement, la capacité.
Bref, vous avez attribué la faute incorrectement. Ce n’est pas l’optimisation qui est à blâmer si on emploie une taille de pas inappropriée, mais bel et bien ladite taille de pas inappropriée.
LikeLike
Effectivement, la capacité d’un modèle ne depend pas de l’optimisation. L’optimisation permet de trouver les constantes d’une fonction que nous essayons d’approximer. Par exemple, si on utilise les fonctions suivantes
f1(x,y) = ax +b
f2(x,y) = ax + by + c
f3(x,y) = ax^2 + by^2 + cx + dy + e
capacité(f1) < capacité(f2) < capacité(f3)
L’optimization nous donne les valeurs a, b, c, d et e. Même si nous incorporons un terme de régularisation pour se prémunir du surapprentissage, la capacité reste pareille.
LikeLike
Je pense que la capacité dépend de la famille des modèles que vous avez choisi pour le problème, et la méthode d’optimisation est seulement une façon de trouver les meilleures paramètres qui fittent ces données. Pour une famille donnée, je pense que la capacité est déjà déterminée, n’importe quelle méthode d’optimisation que vous utilisez…
LikeLike
La réponse donnée en classse est la suivante :
La capacité en temps que propriété instrinsèque d’un modèle est indépendante de l’optimisation.
La capacité effective comportant quant à elle l’ensemble des fonctions potentiellement atteignables par le modèle lors de l’entrainement est dépendante de l’optimisation. L’optimisation peut même jouer un rôle de régularisation dans certains cas.
La capacité effective est plus petite ou égale à la capacité du modèle.
LikeLike
Will quantum annealing solve most classical machine learning optimization shortcomings?
LikeLike
What is quantum annealing ? How does it compare to simulated annealing ? I am not familiar with quantum physics and would appreciate an accessible explanation of what quantum annealing is all about.
I think we already had a discussion on simulated annealing for training NNs but I don’t remember what was said on why it wouldn’t be a good candidate as optimization method. Can someone point to the discussion we had ?
Here is my guess as to why simulated annealing is not so adaptable to NNs.
Since simulated annealing is a special case of the Metropolis-Hastings algorithm, it inherits its advantage of being incredibly flexible in terms of the type of distributions it can sample from, but also the disadvantage of being slow to converge in high-dimension, and being Markov-Chain based, not so amenable to parallelization.
LikeLike
I doubt it. Assume you did manage to express accurately the cost surface of a machine learning problem as an energy landscape, in which particles are let free to settle down to their minimum-energy configuration.
Because of some truly hardcore math related to Schrodinger’s Equation, we know that a particle’s chance of “tunneling” all the way across a barrier decays exponentially with that barrier’s width. That means quantum annealing is at its most beneficial when your cost/energy landscape is stuffed full of tall but thin spikes. I don’t think that’s a priori likely for general problems, for the same reasons we now believe there to be few local minima and many saddle points. Given the extreme number of parameters, it’s almost certain that along some direction the loss function decreases, and so a classical machine can just step around putative tall-but-thin spikes without much trouble.
LikeLike
While simulated (thermal) annealing must climb over energy barriers (or an increasing cost function once at an optimal point) to find a global optimum, simulated quantum annealing can penetrate these barriers (via quantum tunneling). The figure below illustrates the difference between simulated annealing and quantum annealing:

Olexa’s explanation of the limitation of quantum annealing is correct. The larger the thickness of the barrier, the less likely quantum annealing will be able to tunnel through an energy barrier. This can be seen in the figure below

There are little benefits to quantum annealing from C to D.
However, the effects of quantum entanglement in quantum annealing are still not completely understood. “More work is clearly needed to understand if and how entanglement may sign responsible for a quantum speedup of adiabatic quantum optimization” [Hauke et al., “Probing entanglement in adiabatic quantum optimization with trapped ions”, April 2015]
LikeLike
I’m not sure to clearly see what quantum annealing is, but here are some related intuitions.
1. Because parameters space is continuous and is quite a smooth surface (no really high order derivatives), it makes me believe that classical learning machines are classical (in terms of physics) systems.
2. End so, if parameters space would have been discrete (like in case of combinatorial optimization), it may be plausible to threat your problem as quantum system. The tricky part here is to understand that quantum states take discrete values (and an infinite superposition of them, which is not the same thing as being in a continuous space).
By the way, math related to quantum mechanics tunneling can be fairly straightforward if you analyze simple systems such as the 1D barrier potential!
LikeLike
We have seen in earlier lectures that the stochasticity of the gradient improves the learning procedure. However adding a momentum seems like smoothing this stochasticity (control engineers would call it exponential smoothing), but also improves the learning procedure. Isn’t it paradoxal or is it 2 different levels of stochasticity ?
While we are in the control engineering, could we use more sophisticated techniques such as Kalman filtering to find the best trajectory in the parameter space toward a minimized loss ?
LikeLike
Check out Kalman Filtering and Neural Networks by Haykin et al.
LikeLike
Thanks for the suggestion, but this book seems to give a comprehensive material regarding the use of neural networks to improve Kalman filtering.
I was referring to the fact that during training we move in the parameter space following a trajectory that seems to show some regularity since momentum techniques improve learning. There exists more powerful methods to keep the relevant part of the signal (here an approach of the optimal trajectory that leads to a minimum) and get rid of the noise. Kalman filtering is one of them.
LikeLike
The stochasticity of the gradient still survives when using momentum techniques; Directly from the formula we can see it’s just scaled by a factor (1 – momentum). Moreover, the momentum itself has stochasticity, since it’s an exponentially smoothed sum of (past) stochastic gradients. So there’s definitely at least (1 – momentum) units worth of stochasticity there, and they’re still at work regularizing.
What momentum techniques fight is the tendency, within highly-elliptical bowls, to oscillate along the direction of high curvature without making much progress in the direction of low curvature. Intuitively, it does that by making the oscillating components of the past few gradients cancel each other, while amplifying the forward motion of other components when there’s concensus over the past few gradients about the direction to go in.
According to this: http://www.cs.utoronto.ca/~ilya/pubs/2013/1051_2.pdf , if is the condition number of the curvature, then setting the momentum to
is the condition number of the curvature, then setting the momentum to 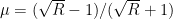 can cut down the number of steps required by
can cut down the number of steps required by 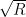 . For very elliptical (ill-conditioned) bowls, that’s an enormous saving.
. For very elliptical (ill-conditioned) bowls, that’s an enormous saving.
Kalman filtering requires the product of a matrix inverse with two other matrices within its update procedure, and careful tuning of the covariance matrices. For a linear dynamical system with 3D pos+vel+acc state, that’s still manageable; For a neural network with 60M+ parameters, that’s impractically expensive, while probably not informing us that much more about the local “environment”. It would almost certainly be more profitable and informative to just make another SGD step. Boyd’s Law of Iteration probably applies here (look it up!).
LikeLike
This is maybe a more technical question but I have tried to use Adam() algorithm for the project. For a small network it was working great however with deeper network (More than 5 layers), it started to do strange things, like forgetting what he has learned after 100 epoch. When I used the same network with a constant learning rate, I haven’t this kind of problem. So is there something to take in consideration with Adam() or other optimization algorithm concerning their hyper-parameters when we add depth in the network ?
LikeLiked by 1 person
An answer from what I understood in class :
RMSProp, Adagrad, Adadelta and Adam (I guess) are algorithms which accumulates gradient statistics during the training. A problem can occure if parameters arrive at a location where those statistics are suddenly not adequate. This situation might affect the learning, and make the model explode. In this situation, a solution could be re-loading the parameters reached just before it went wrong, and re-starting a training from here.
LikeLiked by 1 person
Another question/remark: when we use ReLUs all 2nd derivatives are locally 0, and +infty in zero measure intervals (at points where a neuron reaches a 0). Then it seems that using a first order method is the same as using a 2nd order method because the 2nd order term is 0. While this is definitely true locally this becomes wrong if we consider a neighborhood, because of the infinite value at 0s, but is it one of the reason of the unreasonable effectiveness of the ReLUs, namely without changing anything in the optimization algorithm we are now using a local 2nd order method?
Note that the use of a sigmoid or softmax as a last activation invalidates this remark as it propagates a non-zero 2nd order derivative backwards…
LikeLike
For objective function, we want a smooth function, adding noise is one method. When calculating second derivative, you should be careful, because second derivative may be 0, this is the situation which we do not want.
LikeLike
I note an answer here :
We usually choose a loss function that is not linear piecewise (i.e. cross entropy or l2 distance) so the hessian of the parameters w.r.t the loss is non zero.
Moreover methods that use finite difference do not suffer this issue.
LikeLike
In video 4 of Hinton’s lecture 6, he talks about a way of adaptively setting learning rates based on the product of the signs of the present and previous weight. He said that it only deals with “axis-aligned effects” where as momentum-based methods do not care about the alignment of the axes . It is unclear to me what exactly he is referring to by these “axis-aligned effects”.
LikeLiked by 1 person
Correction: the setting of adaptive learning rates mentioned above uses the sign of the gradients, not of the weights.
LikeLike
Adaptive learning rate methods consider each parameter as independent, so you only consider one dimension at a time while holding all others fixed. In other words, you can only change your steps in directions which are represented by your parameters (the axes of your data). In contrast, 2nd order methods can rescale your space in directions which do not necessarily correspond to the axes represented by parameters.
LikeLike
In video 5 of Hinton’s lecture 6, he said “RPROP is equivalent to using the gradient but also dividing by the size of the gradient”. It is unclear to me in what sense there is that equivalence and how it works. Please elaborate.
LikeLike
To choose an optimization method, does it depend on a model or data? or both of them?
LikeLike
Both.
Usually, if it works for a certain model or for a certain kind of data, it will works for similar model or similar kind of data. Also, for a given order of magnitude of dataset size, the optimization process performance is independent from the number of examples.
It is important to note that the architecture of the model is fundamental in defining what problem it faces when optimizing. (e.g. a feedfoward model with bottlenecks will have a drastically different cost landscape than a similiar feedfoward model with no bottlenecks)
LikeLike
For mini-batch to be an effective tool, we must ensure that classes are properly balanced. I believe that most data set do not exhibit that trait. Generally speaking, I find that the real interesting stuff lies not in the regular but the irregular. Take for example a geological survey that is composed of mostly dirt but once in a while, you will find gold or some other precious commodity; or take the weather were you might find mostly sunny or rainy days but once in a while a hurricane will strike; or the fact that the distribution elements is not uniform in the universe. Are there any general purpose methods that can account for such uneveness? Is this caveat only applicable to the classification problem? Can oddities be detected in an usupervised context?
LikeLike
When Hinton says that the mini-batches must be properly balanced I’m not sure if I completely agree. Perhaps he really meant the class distribution of the minibatches must be the same as the class distribution over the entire training set? As an example, I remember doing ML on an extremely unbalanced dataset (70% of observations belong to class 1, out of 5 classes), and making the class distribution balanced amounted to overfitting, probably because we were overfitting the less common classes in the dataset.
LikeLike
The best way to account for unbalanced classes is to rebalance the classes by oversampling. You can do this by simply repeating examples and applying various transformations in order to multiply and diversify it.
As for oddities, it is often useful to analyse examples that exhibit large gradient norm. The loss for those specific examples will be very large which basicaly means that they would be different from the others.
LikeLike
So we have learned that one of the reason why mini-batches are good is that if there is redundancy in the dataset then each of these mini-batches can “represent” the entire dataset, so a pass through one mini-batch is a lot like a pass through the entire dataset (full batch). I can imagine doing some sort of clustering on a dataset beforehand and constructing a mini-batch from a random example in each cluster (imagine we had lots of these clusters), to create mini-batches that represent the dataset well. It sounds like a neat idea but perhaps it’s not worth the extra computational expense (given how expensive deep learning already can be). Has this been explored?
LikeLike
In class Yoshua said that this is probably not going to be worth the computational cost for minibatches.
However, I’ve found an idea like this very useful in the past. When you have a whole bunch of data that you don’t know much about that you know you’re going to want to do classification on, and suspect that there may be a problem with unbalanced classes, you can do some unsupervised cluster analysis and then weight your classes by the clusters.
LikeLike
In the setup of a constrained optimization problem where there is no analytic form and where we can’t design a different unconstrained optimization problem which has the same solutions. If I understand correctly, the way to solve this problem is to alternate between some gradient step to minimize the generalized Lagrange function wrt x and some gradient step to maximize the KKT multipliers wrt lambda and alpha. It seems tricky to know when to switch between the maximization and the minimization. Is there any other way to go?
LikeLike
On page 279, it is claimed that “training error can in principle be greatly improved by following SGD by a deterministic gradient-based optimization method, but note that it maybe at the cost of worse generalization error.” What exactly is meant here ?
In the next sentence :
“Indeed, generalization error cannotgo down faster than the O(1/k) rate, which corresponds to the statistical rate of convergence (in the best possible case, which is the online case, when everyexample is new), or the Cramer-Rao bound .
I am not sure where the Cramer-Rao bound fits into the discussion. We are familiar with the Cramer-Rao in the context of finding UMVUEs, but I couldn’t quite find the connection here.
LikeLike
Do there exist objective, comparative metrics that measure how effective optimization methods are at extracting and converting “information” about the current neighbourhood (such as current position, local gradient, curvature and past history) into good predictions? I’d imagine this metric could be normalized by the number of parameters, and adjusted for FLOPs or memory required.
For instance, if the random parameter sampler scores 0 units and SGD scores 1 unit, this metric could give a score greater than 1 to SGD+momentum, and an even greater score to Nesterov momentum.
Or maybe no such metric exists, because they’re all good in some situations and suck in others, and so can’t be total-ordered?
LikeLike
The “best” metric for optimization methods is quite simply wall-clock time. Given a fixed computational budget, which method utilizes best this budget to get a minimal loss faster?
LikeLike
I have simple questions about Hinton’s lecture 6a, he said that mini-batch is better than SGD, but I saw that in many applications and even the Theano implementations, the SGD is the default optimization algorithm. I would like to know why the mini-bath is not the first option for many people? Secondly Hinton said that mini-batch works best on balanced class datasets, I can understand the reason behind that. But if the dataset is unbalanced, for example 10% class -1, 90% class +1, what should we do ,if we want to use mini-batch ? Thanks.
LikeLike
I see there might be some confusion in terminology here. SGD can refer to either SGD with mini-batches or SGD with one example at a time (i.e. a mini-batch size of 1). Maybe some people like to refer to the one example case as “SGD” and the mini-batch case as “MSGD”, but I don’t mind calling either of them SGD since they’re both stochastic.
For the last question, I did a Kaggle competition last year (diabetic retinopathy) and for that competition the dataset was really imbalanced (the majority class was 70% and the last class was probably a really low percentage, out of five classes in total). When I experimented with balanced mini-batches, I didn’t get as good performance as I did with mini-batches that conformed to the training set class distribution, probably because the former was overfitting the smaller classes. Another competitor (that scored quite high on the leaderboard) also came to the same observation and did this kind of trick where at the start of training you would feed balanced-class mini-batches to the algorithm but over time you feed it mini-batches that respect the training set distribution. I suppose the intuition behind that technique was to get the neural network to distribute its capacity to all the classes equally but over time encourage the neural network to “come to its senses” and respect the training set class distribution. I can’t comment on that method but I just wanted to bring it up anyway!
I’m not sure I see a problem here (or at least a big problem!); if you feed mini-batches that are distributed differently to the training set, you are not teaching your neural network the distribution of the test set (since we assume the train + test set come from the same distribution). E.g. if class 5 diabetic retinopathy only occurs in 5% of the cases in the training set, I probably don’t want my network to think it occurs in 20% of the training set because it might make a lot more misdiagnoses.
LikeLiked by 1 person