
In this lecture we will continue our discussion of probabilistic undirected graphical models with the Deep Belief Network and the Deep Boltzmann Machine.
Please study the following material in preparation for the class:
- Part of Chapter 20 (sec. 20.1 to 20.8) of the Deep Learning Textbook (deep generative models).
- Slides on deep generative modeling (1 to 25)

As we spoke about in class before, the first few slides talk a lot about the importance of causal relationships between Y and X – if Y is not a causal factor of X, it’s not very useful (and possibly detrimental) to model X based on it.
In the textbook chapter 20.1 on Boltzmann Machines , Hebb’s rule is quoted as “neurons that fire together, wire together”, but I’ve always learned that the rule is better stated as “neurons that consistently/predictably fire together, wire together” – i.e. causality was an important part of Hebb’s postulate.
Are there learning rules (for Boltcmann machines or more generally) which try to take causality into account? Would this be like waiting for a larger number of training examples (e.g. a minibatch) before doing updates?
Could we talk a bit more about causality and how it fits in to probabilistic modeling and machine learning more generally?
LikeLiked by 2 people
Related to what you are asking, there is a paper that appeared on arXiv today called “Building machines that learn and think like people” (http://arxiv.org/pdf/1604.00289v1.pdf). It talks a bit about causal modeling, how it’s important to the future of AI, and how deep learning fits in.
I also found that the two anchor authors (Tenenbaum and Gershman) have done some other interesting related work in the 2000s along these lines. For example, Tenenbaum has a paper called “Learning a Theory of Causality”, which looks at whether you can infer causal relationships from co-occurrence of events. Gershman has a paper called “Reinforcement Learning and Causal Models” (http://gershmanlab.webfactional.com/pubs/RL_causal.pdf), if you are more interested in the interplay between causality and RL. You can find some more interesting papers on the webpages of these two professors.
LikeLiked by 1 person
Thanks!
Just to have a bunch of resources in one place, the main work in establishing a “causal calculus” (based on being able to perform interventions on a system and observe the results) that I know of is Judea Pearl – this is his 2009 textbook: http://bayes.cs.ucla.edu/BOOK-2K/
Yoshua mentioned the research group of Bernard Schoelkopf at Max-Planck which does a lot of research in the area of machine learning and causality.
This is an ICML tutorial from 2012 that I think is a good introduction:
Click to access JanzingSchoelkopf.pdf
And this is a thesis from one of his students which talks about inferring causality from the structure of noise in systems where one cannot make an intervention:
https://github.com/lopezpaz/from_dependence_to_causation/blob/master/from_dependence_to_causation.pdf (I haven’t made it past skimming this, but I’m very interested in this approach and it looks like it might be similar to Tenenbaum’s “Learning a Theory of Causality” that you mentioned?).
LikeLike
That ICML tutorial looks interesting, thanks! I’ve been meaning to go through Pearl’s work, but a whole textbook seems kind of intimidating
LikeLike
Hi,
In the Slides on deep generative modeling, you speak about mixing (for example by Gibbs sampling), what are we exactly trying to do by « mixing »?
LikeLike
I think mixing of a Markov Chain refers to the chain’s convergence to its steady state distribution; so if a Markov Chain has mixed well, further transitions do not significantly alter the distribution it models.
LikeLiked by 3 people
To think about it conceptually/visually, I find it helpful to think of “mixing” as jumping between modes (hills). A good sampler will generate samples that are not centered around one or a few modes, but rather a “well mixed” bunch of modes that are more representative of the data.
LikeLiked by 1 person
May you please clarify the textbook’s Algorithm 20.1 for VSML training of 2-layer DBMs?
What are the marginals you mention?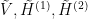 are all discrete Boolean (0 or 1), on account of your use of discrete probabilities in their sampling. But is that the only allowable data type?
are all discrete Boolean (0 or 1), on account of your use of discrete probabilities in their sampling. But is that the only allowable data type?
What are the data types of all the matrices involved? I believe that
Also, layer-wise pretraining of DBMs supposedly requires some nifty footwork involving halving weights everywhere except at the top and bottom, a doubling of the visible units and a special training process for the top and bottom layers. Why?
LikeLike
I’m also not sure about the “marginals”…
Regarding your second question, these matrices represent the “negative persistent particles” (or “fantasy particles”) As you say, the matrices must be binary (0 or 1). However I believe that
must be binary (0 or 1). However I believe that  could possibly be real-valued (if you’re modelling real valued data)
could possibly be real-valued (if you’re modelling real valued data)
As for your third question, after you stack your pretrained RBMs all together to build your DBM, the layers “in the middle” will receive input from below AND from above. However your RBMs were trained to receive input either from below only OR from above only. So, in average, the middle layers will receive twice as much input as before. This is the reason why we halve all the weights.
But then we also need to pay attention to the bottom and top layers (the visibles) whose input will also be halved. To address this we double the visible units.
LikeLiked by 1 person
Can you explain how GAN’s definition of saliency makes it very good at detecting less proeminent yet important features and why it’s ideal for disentangling causal factors.
Is Recurent-GAN possible?
LikeLike
GRAN (Generative Recurrent Adversarial Networks) do exist
Click to access 1602.05110v2.pdf
LikeLike
How does the “walkback training procedure” work and how does it help to speed up convergence?
LikeLike
Look at the picture 1 http://s15.postimg.org/8z8zex66z/Drawing_layer_Export.png
Point B is the probability mass, points nearby will go to the probability mass. And in autoencoder, (look at this picture 2: http://s8.postimg.org/cyhl8p6n9/Drawing_layer_Export_1.png)
x0->x1->x2 is moving down the error , towards higher probability. It corresponds to the situation in picture 1, point B wants to go towards A. But when you go to A , you should go to B, tying to make the model going towards to the nodes on the curve, in this way , it can put energy B lower and A higher. To make this happen, you can add corruption in the autoencoder, and use markov chain to add special kinds of nodes, making the model to chase these nodes: like the B node, instead of randomly add noise.
LikeLike
To add to what @Danlan Chen said, walkback speeds up convergence by, in Yoshua’s own words, “searching and destroying spurious modes”. Instead of injecting random noise, you can track or follow the gradient to spurious modes, and then drop a precision-guided noise bomb to flatten and destroy that mode. It’s much more effective in computational ammunition than carpet-bombing the whole multi-dimensional area hoping to score some hits by pure luck.
LikeLike
It seems that GAN based models are the best to generate nice looking samples, is there any hope for approximate inference based models to perform better on generation than GAN ? Is there maybe a way to combine VAE and GAN ?
LikeLike
To answer your question: I don’t think variational models are too far off from GANs, actually. There are some papers submitted to ICML this year that have more complicated (read: deeper, hierarchical) variational models. For example, see: http://arxiv.org/pdf/1602.05473v1.pdf
As to your other question, it is indeed possible to combine the two. Someone from my lab is working on this; however, as of now the variational part (without the GAN) is more ‘stable’, since you don’t have to worry about balancing the generator and discriminator. Getting GANs working usually involve some hacks to sort this out
LikeLiked by 1 person
To add to this, corresponding to what Yoshua said in class: variational models will actually do ‘infinitely better’ than the GANs quantitatively — that is, in terms of measuring the log likelihood. This is because the GANs will sometimes place 0 probability mass on data that actually comes from your training set, since it is not trained to maximize log likelihood
LikeLike
It was disappointing to read about the lost in popularity of DBNs as the idea (to me) seems very interesting. Does it mean that there is no point into mixing undirected and directed graphical models? You only gain computational and intractable troubles and not much more representational power?
LikeLike
As mentioned in class, the lost in popularity of DBNs is probably mostly due to the fact that we don’t have an efficient training procedure for these models : DBNs have to be trained sequentially, layer by layer.
LikeLike
Bonjour/Hi,
Yes, Guillaume is right, DBN is an interesting model which combines the directed and undirected models, but we have to do layer-wise pre-training and initialize its weight layer by layer, there’s no efficient way to direct train the whole network. And as mentioned in earlier class (Maybe the optimization chapter) It is said on the book on page 536 that “At the time that pretraining became popular, it was understood as initializing the model in a location that would cause it to approach one local minimum rather than another. Today, local minima are no longer considered to be a serious problem…. So maybe it requires to invent other efficient method to train directly the model. There are some papers discussing the difficulty of training DBN in real applications such as this http://users.iit.demokritos.gr/~gtzortzi/docs/publications/Deep%20Belief%20Networks%20for%20Spam%20Filtering.pdf
LikeLike
Is a mixture of models as powerful as a distributed representation (like an RBM or DAE?
LikeLiked by 1 person
In short,
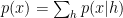 you actually calculate
you actually calculate
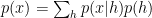 (which is a mixture of sorts)
(which is a mixture of sorts)
for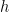 size
size  and
and 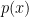 size
size  , you end up having:
, you end up having: components
components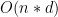 components.
components.
For a Mixture Model:
For RBM:
RBMs share components and thus its smaller. You can efficiently represent any mixture with an RBM but you cannot represent an RBM with a Mixture efficiently.
A paper that was suggested is the following:
Click to access 1206.0387v5.pdf
For the “product of mixtures” this is how it’s defined:
 which is also:
which is also: 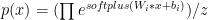
LikeLiked by 2 people
In short,
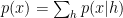 you actually calculate
you actually calculate
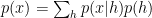 (which is a mixture of sorts)
(which is a mixture of sorts)
for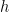 size
size  and
and 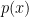 size
size ![[0,1]^d](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D%5Ed&bg=ffffff&fg=000000&s=0&c=20201002) , you end up having:
, you end up having: components
components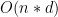 components.
components.
For a Mixture Model:
For RBM:
RBMs share components and thus its smaller. You can efficiently represent any mixture with an RBM but you cannot represent an RBM with a Mixture efficiently.
A paper that was suggested is the following:
Click to access 1206.0387v5.pdf
For the “product of mixtures” this is how it’s defined:
 which is also:
which is also: 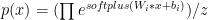
LikeLiked by 1 person